RAG System Model Training
Task
Your tasks:
- Fine-tune retriever & reranker;
- Design prompt to optimize the generation;
- RAG with RL.
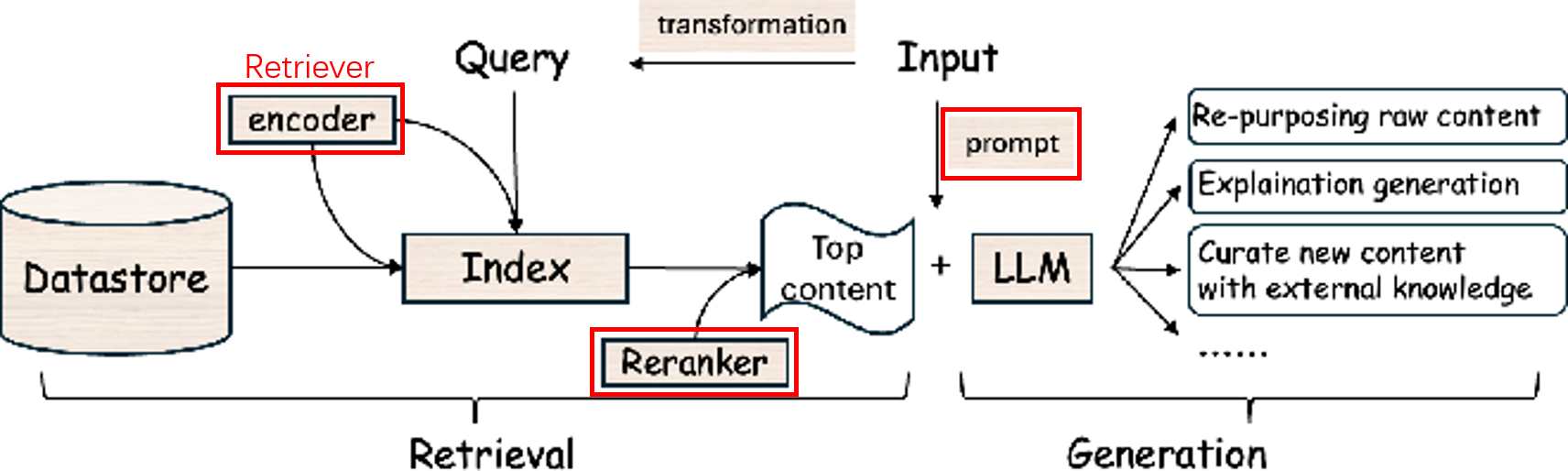
Bi-Encoder & Cross-Encoder
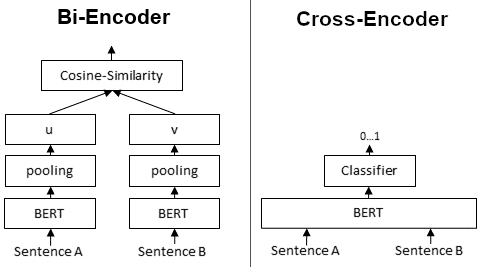
Model
Model checkpoint:
- Retriever: intfloat/multilingual-e5-small
- Reranker: cross-encoder/ms-marco-MiniLM-L12-v2
- LLM: Qwen/Qwen3-1.7B (bf16)
Dataset
Corpus: passages to be retrieved
1 2 3 4 5 6 7
{ "text": "...", "title": "...", "aid": "25749059", "bid": 5, "id": "25749059@5" }
qrels: mappings of queries and their positive passages
1 2 3 4 5 6
{ "qid1":{ "passageId": 1 }, ...... }
Each query has a specific positive passage
train / test_open: train and public test data
1 2 3 4 5 6 7 8 9 10
{ "qid": "...", "rewrite": "...", "evidences": [...], "answer": { "text": "", "answer_start": 0 }, "retrieval_labels": [0, 0, 0, 0, 1] }
- rewrite: query content;
- evidences: passages from BM25 negative sampling;
- retrieval_labels: corresponding true/false label for passages in “evidences”;
The answer can be an exact span of positive passage or CANNOTANSWER in both train and test data;
There can be no positive passage in “evidences” column in
test_open.txt, however, you can find the positive passage id inqrels.txt.
Guides
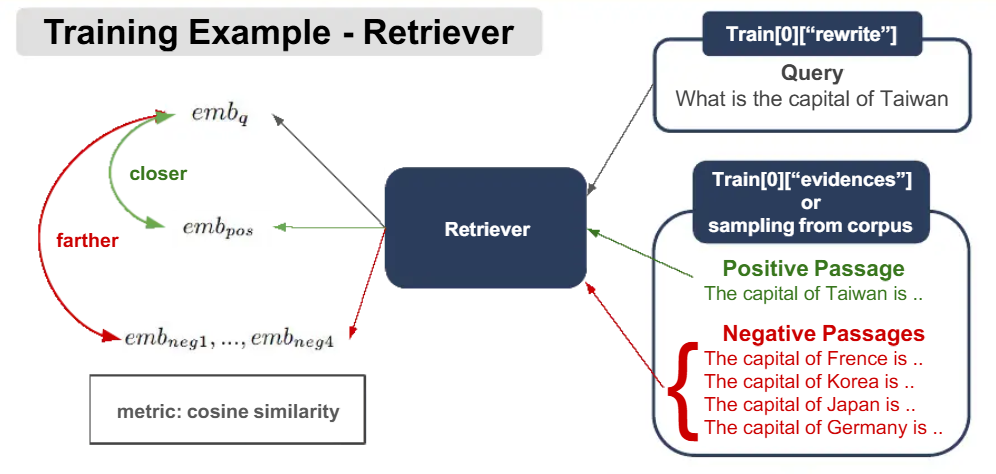
Fine Tune Retriever
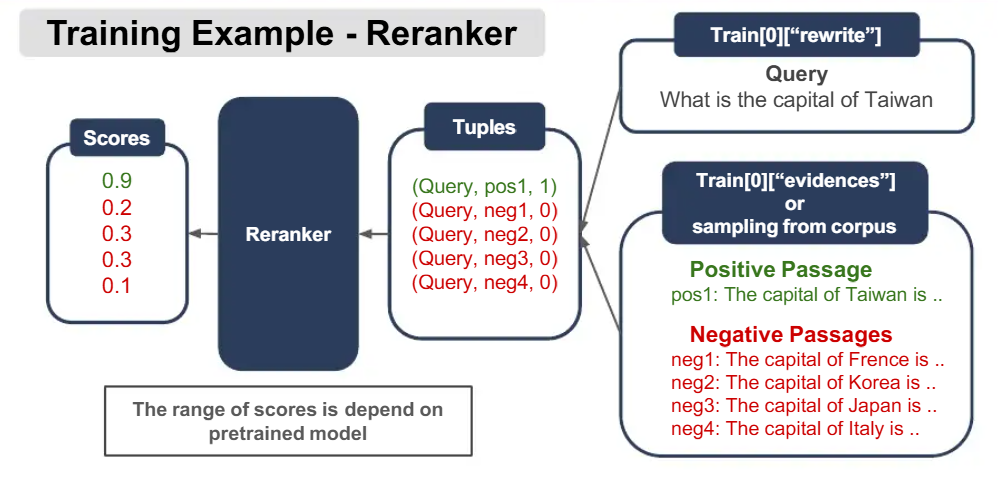
Fine Tune Reranker
RL-RAG Top-M动态决策
Inference
- Pipeline: Load data -> Retriever -> Rerank -> Generate -> Evaluate
- Evaluation metric:
- Recall@k (k=10)
- MRR@k (k=10)
- Sentence similarity from bi-encoder: sentence-transformers/all-MiniLM-L6-v2
Results
| 模型 | Recall@10 | MRR@10 (after rerank) | Bi-Encoder CosSim |
|---|---|---|---|
| Base | 0.8172 | 0.7240 | 0.3656 |
| Fine tune | 0.8549 | 0.7737 | 0.3725 |
| RL-RAG-TOP-M | 0.8549 | 0.7737 | 0.3702 |
Code
Report
Q1: Retriever & Reranker Tuning (5%)
Retriever Training Process (2.5%) and Reranker Training Process (2.5%). Both should include, but are not limited to, the following:
- Clearly describe how the training data is constructed (e.g., anchor, positive sampling, and negative sampling strategies).
- Specify and explain the loss function used for training.
- List the hyper parameters adopted in your experiments
- Provide a training loss curve with at least 5 data points to illustrate the training process. (You can use any package to plot)
Retriever: Bi-Encoder Training
Data Construction
数据来源
- 训练数据:
./data/train.txt - 测试数据:
./data/test_open.txt、./data/qrels.txt、./data/corpus.txt
- 训练数据:
采样策略
训练数据:
- 锚点(Anchor):采集
rewrite字段作为查询文本query; - 正样本(Positive):从
evidences列表中选取retrieval_labels == 1的段落; - 负样本(Negative):同一个batch中的其他正样本(in-batch negatives)、从
evidences列表中选取retrieval_labels == 0的段落(hard negatives)。
1
(anchor, positive, negative_1, …, negative_n)
- 锚点(Anchor):采集
测试数据:
- queries – A dictionary mapping query IDs to queries.
- corpus – A dictionary mapping document IDs to documents.
- relevant_docs – A dictionary mapping query IDs to a set of relevant document IDs.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
# 1. 查询 queries = { "q1": "What is Python?", "q2": "How to install pandas?", } # 2. 文档库(语料) corpus = { "d1": "Python is a programming language.", "d2": "Java is another language.", "d3": "Use pip install pandas to install.", "d4": "Pandas is a data analysis library.", } # 3. 相关文档(ground truth) relevant_docs = { "q1": {"d1"}, # q1 只与 d1 相关 "q2": {"d3", "d4"}, # q2 与 d3、d4 都相关 }
Loss Function
MultipleNegativesRankingLoss(MNRL)是一种对比损失函数,常用于训练嵌入模型,尤其是在语义相似性、释义检测和信息检索等任务中。其旨在最大化正样本对(查询和相关段落)之间的相似度,同时最小化锚点与批次中所有不相关示例(负样本)之间的相似度。
MNRL使用批次内的负样本(in-batch negatives),即批次中所有不匹配的样本对都被视为负样本。例如,在一批 (anchor, positive)对中,其他anchor的正样本充当当前anchor的负样本。这种方法计算效率很高,因为它避免了显式的负样本挖掘,同时每个批次都能提供大量的负样本。
损失函数表示为:
1
L = -log( exp(sim(anchor, positive)) / Σ(exp(sim(anchor, negative_i))) )
$sim()$函数代表相似性度量(例如余弦相似度),分母包含了批次中所有负例。
Hyper-parameters
| 超参数 | 值 | 说明 |
|---|---|---|
| model_name_or_path | intfloat/multilingual-e5-small | base model |
| epochs | 3 | 训练轮次 |
| batch_size | 32 | 批次大小 |
| grad_accumulate_step | 4 | 梯度累积步长 |
| learning_rate | 2e-5 | 学习率 |
| eval_batch_size | 128 | 评估时批次大小 |
| eval_steps | 200 | 每隔200步评估一次 |
完整超参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
training_args = SentenceTransformerTrainingArguments(
output_dir=output_dir,
num_train_epochs=args.epochs,
per_device_train_batch_size=args.batch_size,
gradient_accumulation_steps=args.grad_accumulate_step,
eval_strategy="steps",
eval_steps=args.eval_steps,
save_strategy="steps",
save_steps=args.eval_steps,
save_total_limit=2,
logging_steps=50,
report_to=["tensorboard"],
fp16=True,
warmup_ratio=0.1,
learning_rate=args.learning_rate,
load_best_model_at_end=True,
metric_for_best_model="eval_test_eval_cosine_mrr@10", # ✅ 修正
greater_is_better=True,
remove_unused_columns=False,
)
Loss Curve

训练700个step,loss下降到0.2007。
Reranker: Cross-Encoder Optimization
Data Construction
数据来源
- 训练数据:
./data/train.txt, ` ./data/qrels.txt,./vector_database,passage_index.faiss,passage_store.db` - 测试数据:
./data/test_open.txt、./data/qrels.txt、./data/corpus.txt
- 训练数据:
采样策略
训练数据:
- 查询(Query):采集
rewrite字段作为查询文本query; - 文本(Docs):从
passage_store.db检索; - 标签(Labels): 为每个查询从
passage_store.db中检索文本,如果passage_id在./data/qrels.txt中,标记label=1;否则,label=0。
1 2
(query, [doc1, doc2, …, docN]) [score1, score2, …, scoreN]
- 查询(Query):采集
测试数据:
字典列表,包含以下键:
- ‘query’ (mandatory): The search query.
- ‘positive’ (mandatory): A list of positive (relevant) documents.
- ‘negative’ (optional): A list of negative (irrelevant) documents.
1 2 3 4 5 6 7 8 9 10 11 12
{ "query": "What is Python?", # str: 查询文本 "positive": { # Dict[str, str]: 相关文档 {doc_id: text} "doc_1": "Python is a programming language.", "doc_2": "Python was created by Guido.", }, "negative": { # Dict[str, str]: 不相关文档 {doc_id: text} "doc_3": "Java is a language.", "doc_4": "C++ is compiled.", "doc_5": "Javascript runs in browser.", } }
Loss Function
微调Reranker模型使用了BinaryCrossEntropyLoss和LambdaLoss。
BinaryCrossEntropyLoss(BCE)是sentence-transformers中用于CrossEncoder的基础损失函数,核心思想是:
\[\mathit{L}_{BCE} = -\frac{1}{N}\sum^{N}_{i=1}[y_i \cdot log(\sigma(z_i)) + (1 - y_i) \cdot log(1 - \sigma(z_i))]\]把(查询-文档)对当成二分类问题:相关(1)vs 不相关(0),用交叉熵优化模型输出的概率。
其中:
$N$:样本数量;
$y_i\in{0, 1}$:第$i$个样本的真实标签(1=相关,0=不相关);
$z_i$:CrossEncoder输出的logits(未归一化的实数);
$\sigma(z_i)=\frac{1}{1+e^{-z_i}}$:sigmoid函数,将logits映射为概率$p_i\in(0, 1)$。
LambdaLoss是sentence-transformers中用于CrossEncoder的List-wise排序损失,核心思想是:
直接优化排序指标(NDCG),通过Lambda梯度(交换一对文档对NDCG的影响)来加权pairwise损失,让模型学会把高相关文档往前排。
传统BCE只关心单对好坏,但检索评估看的是整个列表的排序质量(NDCG@10、MRR@10)。LambdaLoss把NDCG的离散不可导问题转化为可导的Lambda梯度。
Lambda梯度
对于文档对$(i, j)$,其中$i$比$j$更相关$(l_i > l_j)$: \(\lambda_{ij} = \frac{\partial NDCG}{\partial s_i} - \frac{\partial NDCG}{\partial s_j} = \frac{-\sigma \cdot \Delta NDCG_{ij}}{1 + e^{\sigma(s_i - s_j)}}\) 其中:
- $s_i, s_j$:模型给文档$i, j$的打分(logits);
- $l_i, l_j$:真实相关度标签(如2 > 1 > 0);
- $\Delta NDCG_{ij}$:交换$i, j$位置导致的NDCG变化(越大越重要);
- $\sigma$:sigmoid 温度(通常 1.0)
损失函数 \(\mathit{L_{Lambda}} = - \sum_{(i, j):l_i > l_j}\lambda_{ij}\cdot log \sigma(s_i - s_j)\)
Hyper-parameters
| 超参数 | 值 | 说明 |
|---|---|---|
| train_file | ./data/reranker_train_hard_neg_1.jsonl | 训练数据 |
| epochs | 1 | 训练轮次 |
| batch_size | 8 | 批次大小 |
| grad_accumulate_step | 4 | 梯度累积步长 |
| eval_batch_size | 128 | 评估时批次大小 |
| learning_rate | 2e-5 | 学习率 |
| eval_steps | 200 | 每隔200步评估一次 |
完整超参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
training_args = CrossEncoderTrainingArguments(
# Required parameter:
output_dir=output_dir,
# Optional training parameters:
num_train_epochs=args.epochs,
per_device_train_batch_size=args.batch_size,
per_device_eval_batch_size=args.eval_batch_size,
gradient_accumulation_steps=args.grad_accumulate_step,
learning_rate=args.learning_rate,
warmup_ratio=0.1,
fp16=True, # Set to False if you get an error that your GPU can't run on FP16
bf16=False, # Set to True if you have a GPU that supports BF16
load_best_model_at_end=True,
# Optional tracking/debugging parameters:
eval_strategy="steps",
eval_steps=args.eval_steps,
save_strategy="steps",
save_steps=args.eval_steps,
save_total_limit=2,
logging_steps=50,
logging_first_step=True,
seed=12,
report_to=["tensorboard"],
# 关键修改:指定实际存在的指标
metric_for_best_model="eval_test_eval_mrr@10", # ✅ 使用 MRR@10 作为评估指标
# 重要:对于 MRR/MAP,越大越好,需设置 greater_is_better=True
greater_is_better=True,
)
Loss Curve

训练950个step,loss下降到0.2457。
Q2: Prompt Optimization (3%)
Provide a detailed explanation of how you designed your prompt. (1.5%)
- Basic:直接告诉模型根据检索到的上下文回答问题;
- CoT:System Prompt让模型按步骤思考,但只输出Final Answer;User Prompt结构化context,对context进行编号输出;
- RAG-Aware No-COT:明确禁止使用外部知识、强调context是唯一信息源、强调grounded answer;不使用CoT,防止模型推理出context之外的东西;
- Basic + 约束:在Basic Prompt基础上,要求模型回答“准确、简介”。
Present at least three different prompts you experimented with, along with their inference performance, to demonstrate the effectiveness of your optimization approach. (1.5%)
Basic Prompt
1 2 3 4 5 6 7 8 9 10 11 12 13
def get_inference_system_prompt() -> str: """get system prompt for generation""" prompt = "Answer the question based on the context below." return prompt def get_inference_user_prompt(query : str, context_list : List[str]) -> str: """Create the user prompt for generation given a query and a list of context passages.""" prompt = f""" Context: {context_list} Question: {query} Answer: """ return prompt
CoT Prompt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
def get_inference_system_prompt() -> str: """ System prompt with controlled Chain-of-Thought reasoning. """ return ( "You are a careful and knowledgeable assistant.\n" "Use the provided context to answer the question.\n" "Follow these steps internally:\n" "1. Identify the key information from the context relevant to the question.\n" "2. Reason step by step to derive the answer.\n" "3. Provide a concise and accurate final answer.\n\n" "Do NOT mention your reasoning steps or the context explicitly.\n" "Only output the final answer." ) def get_inference_user_prompt(query: str, context_list: List[str]) -> str: """ Create user prompt with structured context for RAG + COT. """ context_str = "\n".join( [f"[{i + 1}] {ctx}" for i, ctx in enumerate(context_list)] ) return ( "Here is the retrieved context:\n" f"{context_str}\n\n" "Question:\n" f"{query}\n\n" "Answer:" )
RAG-Aware No-COT Prompt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
def get_inference_system_prompt() -> str: return ( "You are an assistant answering questions strictly based on the given context.\n" "Your answer should closely follow the wording and facts in the context.\n" "Do not add new information or rephrase unnecessarily.\n" "Provide a short, direct answer." ) def get_inference_user_prompt(query: str, context_list: List[str]) -> str: """ Create user prompt with structured context for RAG + COT. """ context_str = "\n".join( [f"[{i + 1}] {ctx}" for i, ctx in enumerate(context_list)] ) return ( "Here is the retrieved context:\n" f"{context_str}\n\n" "Question:\n" f"{query}\n\n" "Answer:" )
Basic + 约束
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
def get_inference_system_prompt(): return "Answer the user concisely based on the context passages." def get_inference_user_prompt(query: str, context_list: List[str]) -> str: """ Create user prompt with structured context for RAG + COT. """ context_str = "\n".join( [f"[{i + 1}] {ctx}" for i, ctx in enumerate(context_list)] ) return ( "Here is the retrieved context:\n" f"{context_str}\n\n" "Question:\n" f"{query}\n\n" "Answer:" )
Method Basic CoT RAG-Aware Basic + 约束 CosSim 0.3588 0.2960 0.3281 0.3656 Basic+约束方法相似度评分最高,CoT方法相似度评分最低。
[!NOTE]
为什么CoT方法相似度评分最低?
尽管CoT能够提升推理能力,但在以embedding similarity评估的RAG测试环境中,反而会降低性能。因为CoT鼓励抽象和改写,从而降低了与标准答案的词汇一致性。即使语义正确,也会导致相似度评分降低。
[!NOTE]
为什么RAG-Aware方法效果反而不如Basic方法?
我们观察到,更简单的提示会产生更高的相似度得分。因为简单的提示允许模型生成在风格和抽象程度上更接近标准答案的回答,而更具限制性的、考虑RAG的提示则会使模型倾向于生成与标准答案分布不同的抽取式回答。
Q3: Additional Analysis (2%)
- Show any interesting analysis using plots or experimental data obtained during inference.
Retriever
使用不同的训练数据和参数微调intfloat/multilingual-e5-small模型,测试结果如下表所示:
| 序号 | 训练数据 | batch_size | grad_accumulate_step | learning_rate | epochs | Recall@10 | MRR@10 (after rerank) | Bi-Encoder CosSim |
|---|---|---|---|---|---|---|---|---|
| 0 | — | — | — | — | — | 0.8172 | 0.7240 | 0.3656 |
| 1 | (anchor, positive) pairs | 32 | 1 | 1e-5 | 3 | 0.8181 | 0.7248 | 0.3643 |
| 2 | (anchor, positive) pairs | 64 | 1 | 1e-5 | 3 | 0.8226 | 0.7286 | 0.3655 |
| 3 | (anchor, positive) pairs | 128 | 1 | 1e-5 | 3 | 0.8294 | 0.7318 | 0.3664 |
| 4 | (anchor, positive, negative_1, …, negative_n) | 32 | 2 | 2e-5 | 3 | 0.8444 | 0.7466 | 0.3674 |
| 5 | (anchor, positive, negative_1, …, negative_n) | 32 | 4 | 2e-5 | 3 | 0.8549 | 0.7585 | 0.3729 |
PS:第0行为base model的测试结果。
- 由于MultipleNegativesRankingLoss使用in-batch negative,因此不断增加batch_size(第1-3行),让模型看到更多的负样本,评价指标Recall@10、MRR@10 (after rerank)、Bi-Encoder CosSim也逐步提升;
- 输入额外的hard negatives(第4-5行),增大选择难度,迫使模型从中选择正确的正样本,从而增强模型能力。
- 更大的批次大小,会导致批次内负样本数量更多,从而提高性能。
Reranker
固定Retriever模型,使用不同的训练数据和参数微调cross-encoder/ms-marco-MiniLM-L12-v2模型,测试结果如下表所示:
| 序号 | 训练数据 | hard negative | loss function | batch_size | grad_accumulate_step | learning_rate | epochs | Recall@10 | MRR@10 (after rerank) | Bi-Encoder CosSim |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | — | — | — | — | — | — | — | 0.8172 | 0.7240 | 0.3656 |
| 1 | (anchor, positive/negative) pairs 1 if positive, 0 if negative | 否 | BCELoss | 128 | 1 | 2e-5 | 1 | 0.8256 | 0.5834 | 0.3579 |
| 2 | (anchor, positive/negative) pairs 1 if positive, 0 if negative | 手动挖掘 | BCELoss | 128 | 1 | 2e-5 | 1 | 0.8549 | 0.7764 | 0.3711 |
| 3 | (query, [doc1, doc2, …, docN]) [score1, score2, …, scoreN] | 否 | RankNetLoss | 32 | 1 | 2e-5 | 1 | 0.8256 | 0.5226 | 0.3546 |
| 4 | (query, [doc1, doc2, …, docN]) [score1, score2, …, scoreN] | 否 | LambdaLoss | 32 | 1 | 2e-5 | 1 | 0.8256 | 0.5133 | 0.3522 |
| 5 | (query, [doc1, doc2, …, docN]) [score1, score2, …, scoreN] | 手动挖掘 | LambdaLoss | 8 | 4 | 2e-5 | 1 | 0.8549 | 0.7737 | 0.3725 |
| 6 | (query, [doc1, doc2, …, docN]) [score1, score2, …, scoreN] | sentence transformers mine_hard_negatives接口 | LambdaLoss | 8 | 4 | 2e-5 | 1 | 0.8549 | 0.7520 | 0.3720 |
PS:第0行为base model的测试结果。
第1行,使用原始
./data/train.txt数据直接微调reranker模型,模型测试效果变差,MRR@10 (after rerank)下降明显,从0.7240降至0.5834。因为训练数据的结构是(1 query + 1 positive + 4 negatives),在这种设置下,reranker只需要学会”把1个positive排在4个negative前面“。这是一个极度简化的排序问题,BCE loss在这里非常”好用“,所以训练时看到MRR稳步上升,但测试时MRR明显下降。在独立测试时,实际上是在做:
1 2 3
Bi-Encoder Top-10 candidates → CrossEncoder rerank → 看相关文档排第几
在这个场景里,Top-10里的negative都是hard negative,它们语义相近、词汇重叠、甚至部分相关。这是一个完全不同、难得多的问题。于是,就出现了训练与实际rerank目标的错位:
阶段 模型学到的能力 训练 区分「明显正 vs 明显负」 实际 rerank 在「一堆都很像的候选」里精细排序
结果就是,正样本还在Top-10(Recall@10还不错),但被排到靠后的位置,导致MRR@10直接崩。
- 第2行相比第1行,使用手动挖掘的hard negative数据训练,模型测试效果显著提升。
- 第3-4行,使用原始
./data/train.txt数据直接微调reranker模型,模型测试效果变差。原因与第1行类似,主要问题出在训练数据上。 - 第5-6行,分别使用手动挖掘和sentence transformers mine_hard_negatives接口获取hard negative数据,模型测试效果均显著提升,且区别不大。这里推荐使用sentence transformers mine_hard_negatives接口,胜在方便。
- 对比第2、5、6行,使用BCELoss或是LambdaLoss对训练的影响不是很大。
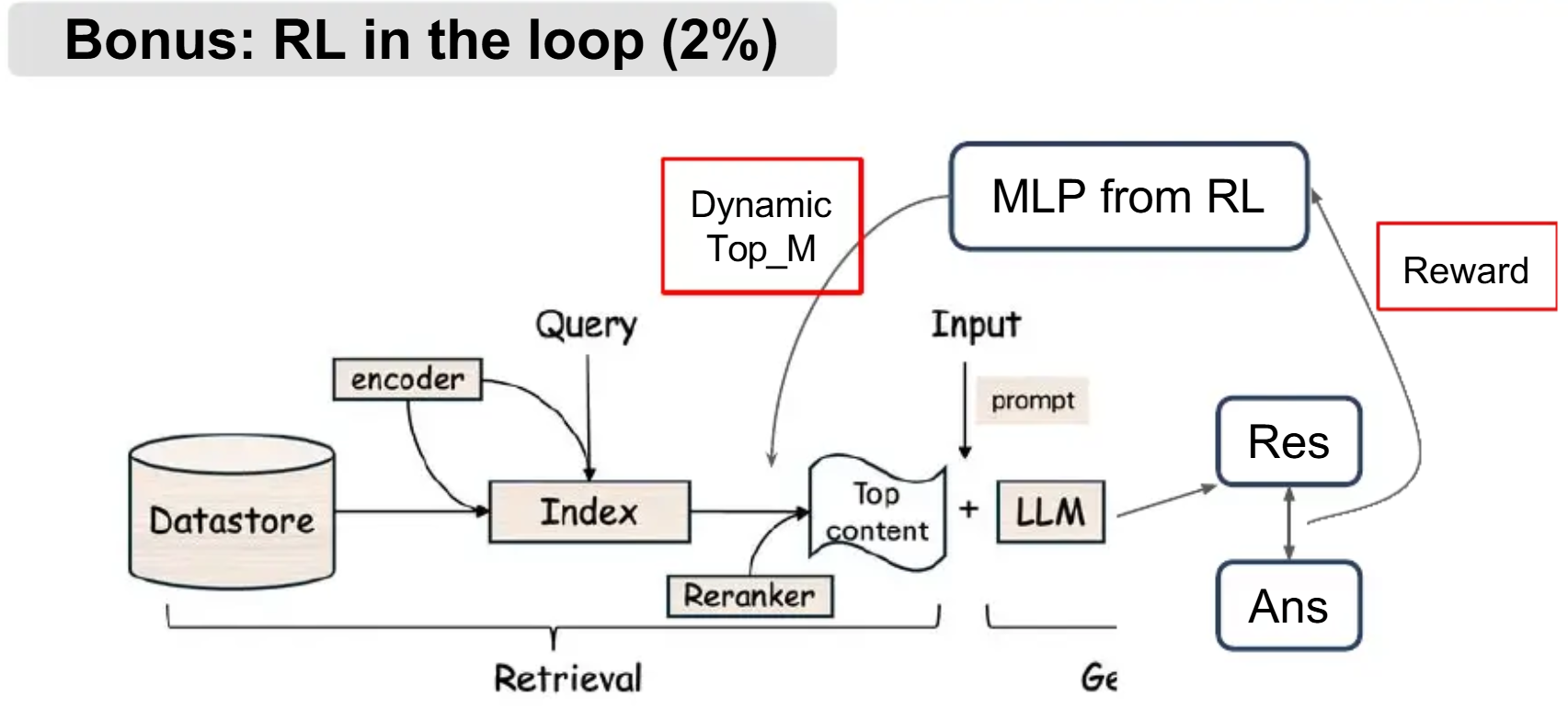
Q4:RL in the loop(2%)
Use Reinforcement Learning to train a model deciding the number of passages to include in the prompt.
- Describe your training method and experimental setting to compare with the original results.
使用强化学习算法预测reranker模型每次使用的passage数量top_m。每个episode只有一个step,即选择top_m,该任务本质上是Contextual Bandit,不是full RL。
因为在线训练PPO policy时,一边跑LLM一边在线探索,运行速度太慢并且噪声大。实作时,采用Offline RL + PPO微调policy策略。
PPO + Offline RL步骤是:
- 先离线采集 RAG 数据;
- 构造 (state, action, reward) dataset;
- 用 PPO 在离线环境中训练;
- 再上线只做 Top-M 决策;
原始:
1
Query → Retrieve → Rerank → RL → Top_M → LLM → Reward
改成 Offline RL:
1
2
3
4
5
6
7
8
Phase1: Collect Dataset (once)
Query → Retrieve → Rerank → enumerate M → LLM → reward → save
Phase2: Offline PPO Train
(state, action, reward) → PPO → policy
Phase3: Online Inference
Query → Retrieve → Rerank → PPO → Top_M → LLM
Phase 1:离线数据采集
对每个query,运行不同的top_m,保存数据。
1
2
3
4
5
6
7
8
9
10
11
12
# Offline Dataset结构
sample = {
"state": state,
"action": int(m),
"reward": float(reward),
"next_state": state,
"done": True,
"qid": env.current_qid,
"top_m": m + 1,
"reward_info": info, # reward各项具体数值
"pred_ans": pred_ans # LLM生成的回答
}
Phase 2:Offline PPO Environment
构造一个假的GymEnv,从dataset中采样。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
class OfflineBanditEnv(gym.Env):
"""
1-step Offline Contextual Bandit Environment
Designed for PPO training
"""
def __init__(self, offline_dataset):
super().__init__()
# -------- Build index --------
self.qid_to_state = {}
self.qid_to_action_reward = defaultdict(dict)
for item in offline_dataset:
qid = item["qid"]
state = np.array(item["state"], dtype=np.float32)
action = int(item["action"])
reward = float(item["reward"])
self.qid_to_state[qid] = state
self.qid_to_action_reward[qid][action] = reward
self.qids = list(self.qid_to_state.keys())
# -------- Spaces --------
example_state = next(iter(self.qid_to_state.values()))
self.state_dim = len(example_state)
self.action_dim = max(
max(actions.keys()) for actions in self.qid_to_action_reward.values()
) + 1
self.observation_space = spaces.Box(
low=-np.inf,
high=np.inf,
shape=(self.state_dim,),
dtype=np.float32
)
self.action_space = spaces.Discrete(self.action_dim)
# current episode state
self.current_qid = None
self.current_state = None
# --------------------------------
# reset()
# --------------------------------
def reset(self, seed=None, options=None):
super().reset(seed=seed)
self.current_qid = random.choice(self.qids)
self.current_state = self.qid_to_state[self.current_qid]
return self.current_state, {}
# --------------------------------
# step()
# --------------------------------
def step(self, action):
action = int(action)
# lookup reward
reward = self.qid_to_action_reward[self.current_qid].get(action, 0.0)
terminated = True
truncated = False
info = {
"qid": self.current_qid,
"selected_action": action,
}
return self.current_state, reward, terminated, truncated, info
Phase 3:PPO Training
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
logging.info("Training PPO offline...")
offline_dataset = load_offline_data(args.rl_offline_data)
env = OfflineBanditEnv(offline_dataset)
# Contextual Bandit PPO
model = PPO(
"MlpPolicy",
env,
learning_rate=3e-4,
gamma=0.0, # single step bandit
n_steps=2048,
batch_size=256,
verbose=1,
tensorboard_log="./output/rl/ppo/runs"
)
model.learn(total_timesteps=100000)
model.save(args.output_dir)
logging.info(f"RL model saved to {args.output_dir}")
Phase 4:Online 推理使用 PPO
1
2
3
4
5
6
7
# Batched forward pass through the PPO policy
with torch.no_grad():
policy = ppo_model.policy
# get_distribution handles feature extraction + action distribution
dist = policy.get_distribution(obs_tensor)
# Deterministic: take the mode (argmax) of the distribution
actions = dist.mode() # (B,)
Observation 设计
一个好的 Top_M state 应该包含:
| 类别 | 示例 |
|---|---|
| Score Shape | topK scores |
| Distribution | mean / std / max / min |
| Gap | s1-s2, s1-sK |
| Entropy | retrieval entropy |
| Query Info | length, embedding norm |
| Cost Proxy | avg passage length |
Reward设计
Top_M 的真实目标是:
1
maximize: AnswerQuality − λ · ContextCost
reward=Quality(pred,gold)−λ⋅TokenCost(context)
| 模块 | 作用 |
|---|---|
| Semantic | embedding cosine |
| Lexical | 中文 Rouge-L |
| Cost | token cost penalty |
| Normalize | bounded for PPO |
1
reward = w1 * cosine + w2 * rouge_l - λ * token_cost
Additional Analysis
PPO policy训练loss如图:

分析Ground Truth,83.5%的query都只对应一个passage,即top_m=1。
1
2
3
4
5
6
7
8
平均每个 query 有 1.18 个相关文档
最少: 1, 最多: 4
分布:
1 个相关文档: 2790 个 queries (83.5%)
2 个相关文档: 522 个 queries (15.6%)
3 个相关文档: 27 个 queries (0.8%)
4 个相关文档: 3 个 queries (0.1%)
使用PPO模型预测top_m,对所有query预测的top_m都是1。这种行为在统计上是合理的,并不是PPO collapse。reward结构在数学上强烈偏向top_m=1,PPO学成常数1是”正确优化结果“,不是bug。
reward=tanh(quality−λ⋅cost−0.01⋅M)
其中:
- $quality \in [0,1]$
- $cost=tanh(ctx_tokens / 800)$
- $\lambda = 0.2$
- $m_ penalty = 0.01\cdot M$
关键问题
cost是单调递增的
cost=tanh(ctx_tokens/800)ctx_tokens和top_m正相关,所以:
M↑⇒cost↑⇒reward↓但是,quality未必会随着M增加。如果Top 1已经够好,增加passage只会增加token、引入噪声、降低cosSim。
惩罚了两次top_m
已经有
lambda_cost * cost,又增加m_penalty = 0.01 * M,相当于双重惩罚context:reward=quality−0.2∗cost−0.01M例如:如果平均每passage 200 tokens:
top_m=1 -> 200 tokens
top_m=2 -> 400 tokens
1 2
cost(200) ≈ tanh(0.25) ≈ 0.24 cost(400) ≈ tanh(0.5) ≈ 0.46
惩罚差$0.2∗(0.46−0.24)≈0.044$,再加$0.01$,总共$≈ 0.054$,这比quality的提升空间还大。
tanh压缩
1 2
reward = quality - lambda_cost * cost - m_penalty reward = float(np.tanh(reward))
如果reward本身已经偏负,负reward会放大梯度影响,进一步推动PPO避开top_m>1。
1 2
-0.2 → tanh(-0.2) ≈ -0.197 -0.4 → tanh(-0.4) ≈ -0.38
[!IMPORTANT]
- 因此不是PPO的问题,而是reward设计问题。目前reward本质在优化”尽量少用context“,而不是”尽量提升CosSim“。
- 使用PPO模型推理top_m,Bi-Encoder CosSim从0.3725降低到0.3702,约0.617%;LLM推理使用passag数量从3篇降低到1篇,约66.67%。