Ceph介绍、搭建集群及使用
Ceph介绍
Ceph存储简介
Ceph是一个可靠、自动均衡、自动恢复的分布式存储系统,通常可用于对象存储,块设备存储和文件系统存储。 Ceph在存储的时候充分利用存储节点的计算能力,在存储每一个数据时都会通过计算得出该数据的位置,尽量的分布均衡。
Ceph存储组件
Ceph核心组件包括:
- OSD
- Monitor
- MDS
OSD:英文全称为Object Storage Device,主要功能用于数据的存储,当直接使用硬盘作为存储目标的时候,一块硬盘称之为OSD。当使用一个目录作为存储目标的时候,这个目录也称之为OSD。 Monitor:负责监视整个Ceph集群运行Map图,维护Ceph集群的状态。还包括了集群中客户端的认证与授权。 MDS:英文全称为Metadata Server,主要文件系统服务的元数据,对象存储和块设备存储不需要元数据服务。如果集群中使用CephFS接口,那么至少集群中至少需要部署一个MDS服务。 在新版本的Ceph还有其它组件,如:Manager。此组件在L版(Luminous)和之后的版本支持,是一个Ceph守护进程,用于跟踪运行时指标和集群的当前状态,如存储利用率,系统负载。通过基于Python插件来管理和公开这些信息,可基于Web UI和Rest API。如果要对此服务进行高可用至少需要两个节点。
Rados存储集群
RADOS为一个Ceph名词,通常指ceph存储集群,英文全名Reliable Automatic Distributed Object Store。即可靠的、自动化的、分布式对象存储系统。
Librados介绍
Librados是RADOS存储集群的API,支持常见的编程语言,如:C、C++、Java、Python、Ruby和PHP等。 通常客户端在操作RADOS的时候需要通过与Librados API接口交互,支持下面几种客户端:
- RBD
- CephFS
- RadosGW
RBD:Rados Block Devices此客户端接口基于Librados API开发,通常用于块设备存储,如虚拟机硬盘。支持快照功能。 RadosGW:此客户端接口同样基于Librados API开发,是一个基于HTTP Restful风格的接口。 CephFS:此客户端原生的支持,通常文件系统存储的操作使用CephFS客户端。如:NFS挂载。 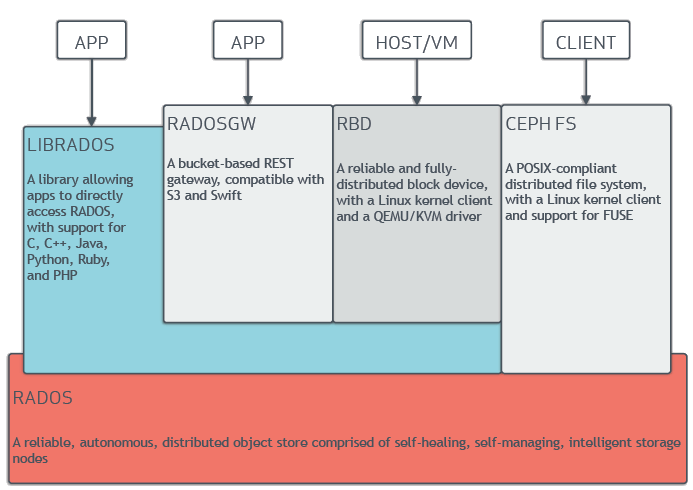
管理节点
Ceph常用管理接口通常都是命令行工具,如rados、ceph、rbd等命令,另外Ceph还有可以有一个专用的管理节点,在此节点上面部署专用的管理工具来实现近乎集群的一些管理工作,如集群部署,集群组件管理等。
Pool与PG
Pool是一个存储对象的逻辑分区,它通常规定了数据冗余的类型与副本数,默认为3副本。对于不同类型的存储,需要单独的Pool,如RBD。每个Pool内包含很多个PG。 PG是归置组,英文名为Placement Group,它是一个对象的集合,服务端数据均衡和恢复的最小单位就是PG。
FileStore与BlueStore
FileStore是老版本默认使用的后端存储引擎,如果使用FileStore,建议使用xfs文件系统。 BlueStore是一个新的后端存储引擎,可以直接管理裸硬盘,抛弃了ext4与xfs等本地文件系统。可直接对物理硬盘进行操作,同时效率也高出很多。
Object对象
在Ceph集群中,一条数据、一个配置都为一个对象。这些都是存储在Ceph集群,以对象进行存储。每个对象应包含ID、Binary Data和Metadata。
工作原理
底层存储机制:RADOS把多个节点组织为一个集群,并利用对方的存储空间整合成更大的存储空间,从而提供分布式存储服务。
图
https://www.modb.pro/db/634328 一句话概括:对象映射给PG—-》PG映射给osd,过程由CRUSH算法来完成。
部署Ceph
环境
硬件:
- 服务器:2288H V5
- Cpu:Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz // 90.91.33.57, 90.91.33.58, 90.91.33.60, 90.91.33.62
OS:
- CentOS Linux release 7.6.1810 (Core)
个人环境:
| 主机名 | IP | 网卡模式 | 内存 | 系统盘 | 数据盘 | 备注 |
|---|---|---|---|---|---|---|
| ceph-1(node57) | 90.91.33.57 | cpu | ||||
| ceph-2(node58) | 90.91.33.58 | cpu | ||||
| ceph-3(node60) | 90.91.33.60 | cpu | ||||
| ceph-client(node62) | 90.91.33.62 | cpu |
基础配置
修改主机名称
修改主机名为了方便区分,不改也可以,可以区分开就好。
主机配置为ceph1, ceph2, ceph3; 客户机配置为ceph-client
1 2 3 4 5 6 7 8
[root@localhost ~]# hostnamectl set-hostname ceph-1 [root@ceph-1 ~]# bash [root@localhost ~]# hostnamectl set-hostname ceph-2 [root@ceph-2 ~]# bash [root@localhost ~]# hostnamectl set-hostname ceph-3 [root@ceph-3 ~]# bash [root@localhost ~]# hostnamectl set-hostname ceph-client [root@ceph-clinet ~]# bash
配置hosts文件映射
1
vim /etc/hosts
在各个集群和客户端节点的“/etc/hosts”中添加如下内容:
1 2 3 4
90.91.33.57 node57 90.91.33.58 node58 90.91.33.60 node60 90.91.33.62 node62
关闭防火墙 关闭本节点防火墙,需在所有Ceph节点和Client节点依次执行如下命令。
1 2 3
systemctl stop firewalld systemctl disable firewalld systemctl status firewalld
配置ssh免密登录 使用 ssh-keygen 命令生成公钥、私钥(一直按回车),再使用 ssh-copy-id 命令将公钥copy复制到目标主机,最后使用一个for循环测试是否可免密登录。 在node57(ceph-1)上操作
1 2 3 4 5
ssh-keygen -t rsa ssh-copy-id node57 ssh-copy-id node58 ssh-copy-id node60 ssh-copy-id node62测试是否可免密登录
1
for i in 57 58 60 62; do ssh node$i hostname; done
配置yum源 在所有集群和客户端节点配置epel源。
1
yum install epel-release -y
配置时间同步 Ceph为什么要时间同步?
1
它是一个分布式存储系统,其中的各个节点需要协同工作。如果节点之间的时间不同步,可能会导致数据不一致或者丢失。例如,如果某个节点的时间比其他节点早,它可能会认为某个对象已经被删除,而其他节点还在继续使用该对象。这种不一致性可能会导致数据损坏或丢失。因此,为了保证数据的一致性和可靠性,Ceph要求节点之间的时间同步。
node57节点执行:
1 2 3 4 5
[root@node57 /]# sed -i '3,6s/^/#/g' /etc/chrony.conf [root@node57 /]# sed -i '7s/^/server ceph-1 iburst/g' /etc/chrony.conf [root@node57 /]# echo "allow 90.91.33.0/24" >> /etc/chrony.conf [root@node57 /]# echo "local stratum 10" >> /etc/chrony.conf [root@node57 /]# systemctl restart chronyd && systemctl enable chronyd
node58, node60, node62节点执行:
1 2 3 4
sed -i '3,6s/^/#/g' /etc/chrony.conf sed -i '7s/^/server node57 iburst/g' /etc/chrony.conf systemctl restart chronyd && systemctl enable chronyd chronyc sources
创建ceph集群
安装ceph软件
配置Ceph镜像源
在所有集群和客户端节点建立ceph.repo。
1
vi /etc/yum.repos.d/ceph.repo
加入如下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
[Ceph] name=Ceph packages for $basearch baseurl=http://download.ceph.com/rpm-nautilus/el7/$basearch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc priority=1 [Ceph-noarch] name=Ceph noarch packages baseurl=http://download.ceph.com/rpm-nautilus/el7/noarch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc priority=1 [ceph-source] name=Ceph source packages baseurl=http://download.ceph.com/rpm-nautilus/el7/SRPMS enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc priority=1
更新Yum源
1
yum clean all && yum makecachenode57
1 2
yum install ceph-deploy ceph python-setuptools -y ceph-deploy --version
node58, node60
1
yum install ceph python-setuptools -y
如果安装提示以下错误信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44
Error: Package: 2:ceph-radosgw-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0()(64bit) Error: Package: 2:librbd1-14.2.11-0.el7.x86_64 (ceph) Requires: liblttng-ust.so.0()(64bit) Error: Package: 2:ceph-base-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0()(64bit) Error: Package: 2:librados2-14.2.11-0.el7.x86_64 (ceph) Requires: liblttng-ust.so.0()(64bit) Error: Package: 2:ceph-base-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0(LIBOATH_1.10.0)(64bit) Error: Package: 2:ceph-base-14.2.11-0.el7.x86_64 (ceph) Requires: liblttng-ust.so.0()(64bit) Error: Package: 2:ceph-common-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0(LIBOATH_1.10.0)(64bit) Error: Package: 2:ceph-mon-14.2.11-0.el7.x86_64 (ceph) Requires: libleveldb.so.1()(64bit) Error: Package: 2:ceph-osd-14.2.11-0.el7.x86_64 (ceph) Requires: libleveldb.so.1()(64bit) Error: Package: 2:ceph-base-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0(LIBOATH_1.2.0)(64bit) Error: Package: 2:ceph-common-14.2.11-0.el7.x86_64 (ceph) Requires: libleveldb.so.1()(64bit) Error: Package: 2:ceph-common-14.2.11-0.el7.x86_64 (ceph) Requires: libbabeltrace.so.1()(64bit) Error: Package: 2:ceph-common-14.2.11-0.el7.x86_64 (ceph) Requires: libbabeltrace-ctf.so.1()(64bit) Error: Package: 2:ceph-mgr-14.2.11-0.el7.x86_64 (ceph) Requires: python-bcrypt Error: Package: 2:ceph-common-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0(LIBOATH_1.2.0)(64bit) Error: Package: 2:ceph-base-14.2.11-0.el7.x86_64 (ceph) Requires: libleveldb.so.1()(64bit) Error: Package: 2:librgw2-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0()(64bit) Error: Package: 2:ceph-mgr-14.2.11-0.el7.x86_64 (ceph) Requires: python-pecan Error: Package: 2:ceph-base-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0(LIBOATH_1.12.0)(64bit) Error: Package: 2:librgw2-14.2.11-0.el7.x86_64 (ceph) Requires: liblttng-ust.so.0()(64bit) Error: Package: 2:ceph-common-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0()(64bit) You could try using --skip-broken to work around the problem You could try running: rpm -Va --nofiles --nodigest
这时候需要更新安装一下依赖包 ,就可以完美解决
1
yum install -y yum-utils && yum-config-manager --add-repo https://dl.fedoraproject.org/pub/epel/7/x86_64/ && yum install --nogpgcheck -y epel-release && rpm --import /etc/pki/rpm-gpg/R
部署MON节点
仅需在主节点node57节点上执行。
ceph.conf:ceph配置文件 ceph-deploy-ceph.log:日志文件 ceph.mon.keyring:mon密钥文件(mon之间通信会用到)
创建集群:
1 2
cd /etc/ceph ceph-deploy new node57 node58 node60在“/etc/ceph”目录下自动生成的ceph.conf文件中配置网络mon_host、public network、cluster network
1
vim /etc/ceph/ceph.conf
将ceph.conf中的内容修改为如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
[global] fsid = 8743b02c-4e8c-4650-bdd6-0f9c4f0fd0f7 mon_initial_members = node57, node58, node60 mon_host = 90.91.33.57,90.91.33.58,90.91.33.60 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx public_network = 90.91.33.0/24 cluster_network = 90.91.33.0/24 [mon] mon_allow_pool_delete = true
public_network用于存储节点与计算节点的数据交互,cluster_network用于内部存储集群之间的数据同步(仅在存储节点间使用),目的是将内部集群间的网络与外部访问的网络隔离,通常应该是不同的Ip。
初始化监视器并收集密钥:
1
ceph-deploy mon create-initial
将“ceph.client.admin.keyring”拷贝到各个节点上
1
ceph-deploy --overwrite-conf admin node57 node58 node60 node62
查看是否配置成功
1
ceph -s
部署MGR节点
仅需在主节点node57节点上执行。
1
ceph-deploy mgr create node57 node58 node60
查看MGR是否部署成功
1
ceph -s结果如下所示:
部署OSD节点 “sda”代表系统中的第一个磁盘,而“sdb”、“sdc”则代表系统中的第二个磁盘和第三个磁盘。如果系统中有更多的磁盘,则可以继续使用“sd”命名方式,例如“sdd”、“sde”等等。 在ceph集群中。Administrators、Monitors、Managers和MDSs节点节点对服务器硬盘都没有要求,只要系统能正常运行即可。但OSD节点不一样,通常一个OSD就代表一块物理硬盘,作为分布式存储,OSD越多越好。 划分OSD分区:
查看各服务器磁盘占用情况:
1
lsblk
node57 sdb磁盘空闲,可用用作OSD。
node58 没有空闲磁盘可供OSD使用
node60
sdb磁盘空闲,可用用作OSD。
在node57,node60的sdb上划分10GB的空间作为OSD。
创建分区
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
[root@node57 ceph]# sudo parted /dev/sdb GNU Parted 3.1 Using /dev/sdb Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) mklabel msdos (parted) unit GB (parted) mkpart Partition type? primary/extended? primary File system type? [ext2]? ext4 Start? 0.00GB End? 10.00GB (parted) print Model: HUAWEI HWE52SS36T4M002N (scsi) Disk /dev/sdb: 6401GB Sector size (logical/physical): 512B/4096B Partition Table: msdos Disk Flags: Number Start End Size Type File system Flags 1 0.00GB 10.0GB 10.0GB primary
- sdb下已新增分区sdb1
格式化分区
将/dev/sdb1分区格式化为ext4类型
1
ext4是一种Linux文件系统类型,是ext3文件系统的后继版本。它是Linux内核的一部分,支持更大的文件和分区大小,更快的文件系统检查和更好的性能。它还提供了更好的数据一致性和更高的可靠性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
```bash [root@node57 ceph]# sudo mkfs.ext4 /dev/sdb1 mke2fs 1.42.9 (28-Dec-2013) Discarding device blocks: done Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 610800 inodes, 2441216 blocks 122060 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=2151677952 75 block groups 32768 blocks per group, 32768 fragments per group 8144 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632 Allocating group tables: done Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done ``` ```输入“lsblk -f”并按回车,查看/dev/sdb1是否格式化为ext4类型。 ```
挂载分区(用作OSD的分区会被Ceph独占,不能挂载文件夹,跳过此步)
1 2 3 4 5
创建文件夹`/data`,将分区sdb1挂载在上面。 ```bash [root@node57 ceph]# sudo mkdir /data [root@node57 ceph]# sudo mount /dev/sdb1 /data检查是否成功挂载上新创建的分区。
1 2 3
[root@node57 ceph]# df -h /dev/sdb1 Filesystem Size Used Avail Use% Mounted on /dev/sdb1 9.1G 37M 8.6G 1% /data
部署OSD节点
node57执行
1 2
ceph-deploy osd create node57 --data /dev/sdb1 ceph-deploy osd create node60 --data /dev/sdb1
创建OSD失败,错误信息如下:/dev/sdb1已经挂载,因此不能独占访问。
原因:sdb1已经挂载了文件夹
/data,在独占访问文件系统之前,需要卸载/data。1
sudo umount /dev/sdb1查看osd状态
1
ceph -s2个osd的状态都是up
使用Ceph
Ceph是一个集可靠性、可扩展性、统一性的分布式存储系统,提供对象(Object)、块(Block)及文件系统(File System)三种访问接口,它们都通过底层的 LIBRADOS 库与后端的对象存储单元(Object Storage Device,OSD)交互,实现数据的存储功能。
CephFs文件系统
配置MDS节点 MDS(Metadata Server)即元数据Server主要负责Ceph FS集群中文件和目录的管理。配置MDS节点如下: 创建MDS。在node57节点执行:
1 2
cd /etc/ceph ceph-deploy mds create node57 node58 node60在Ceph各个节点上查看是否成功创建MDS进程。
1
ps -ef | grep ceph-mds | grep -v grep
创建存储池和文件系统
CephFS需要使用两个Pool来分别存储数据和元数据,分别创建fs_data和fs_metadata两个Pool。 Ceph集群中的PG总数:
1
PG总数 = (OSD总数 * 100) / 最大副本数
结果必须舍入到最接近的2的N次方幂的值,本例中取128。 在node57上执行以下命令创建存储池。
1 2
ceph osd pool create fs_data 128 128 ceph osd pool create fa_metadata 64 64
命令中的fs_data是存储池名字,128分别是pg、pgp的数量,fs_metadata同理。
基于上述存储池创建新的文件系统。
1
ceph fs new cephfs fs_metadata fs_data
cephfs为文件系统名称,fs_metadata和fs_data为存储池名称,注意先后顺序。 查看创建的CephFS。
1
ceph fs ls客户机挂载文件系统 在Client节点node62查看客户端访问Ceph集群密钥。
1
cat /etc/ceph/ceph.client.admin.keyring创建文件系统挂载点,在node62执行。
1
mkdir /mnt/cephfs在node62执行。
1
mount -t ceph 90.91.33.57:6789,90.91.33.58:6789,90.91.33.60:6789:/ /mnt/cephfs -o name=admin,secret=AQCgfVRl06p9DhAAvx2FeW++PyH5OXuCURk0wg==,sync
MON默认端口号为6789,-o参数指定集群登录用户名和密钥(secret=步骤1查看到的key)。在node62检查是否挂载成功,文件系统类型是否为ceph。
1
stat -f /mnt/cephfs
块存储
创建存储池,存储池命名为vdbench。
1 2
cd /etc/ceph ceph osd pool create vdbench 8 8
Ceph 14.2.22版本创建存储池后,需指定池类型(CephFS、RBD、RGW)三种,本文以创建块存储为例。
1
ceph osd pool application enable vdbench rbd创建块设备 创建两个块设备image1、image2
1 2
rbd create image1 -s 2048 --pool vdbench --image-format 2 --image-feature layering rbd create image2 -s 2048 --pool vdbench --image-format 2 --image-feature layering
查看image1 检查是否创建成功
1
rbd ls -p vdbench
输出结果中包含image1、image2,说明创建成功。
=======
title: Ceph介绍、搭建集群及使用 date: 2024-08-26 14:40:00 +/-8 categories: [AI for System] tags: [ceph] # TAG names should always be lowercase —
Ceph介绍
Ceph存储简介
Ceph是一个可靠、自动均衡、自动恢复的分布式存储系统,通常可用于对象存储,块设备存储和文件系统存储。 Ceph在存储的时候充分利用存储节点的计算能力,在存储每一个数据时都会通过计算得出该数据的位置,尽量的分布均衡。
Ceph存储组件
Ceph核心组件包括:
- OSD
- Monitor
- MDS
OSD:英文全称为Object Storage Device,主要功能用于数据的存储,当直接使用硬盘作为存储目标的时候,一块硬盘称之为OSD。当使用一个目录作为存储目标的时候,这个目录也称之为OSD。 Monitor:负责监视整个Ceph集群运行Map图,维护Ceph集群的状态。还包括了集群中客户端的认证与授权。 MDS:英文全称为Metadata Server,主要文件系统服务的元数据,对象存储和块设备存储不需要元数据服务。如果集群中使用CephFS接口,那么至少集群中至少需要部署一个MDS服务。 在新版本的Ceph还有其它组件,如:Manager。此组件在L版(Luminous)和之后的版本支持,是一个Ceph守护进程,用于跟踪运行时指标和集群的当前状态,如存储利用率,系统负载。通过基于Python插件来管理和公开这些信息,可基于Web UI和Rest API。如果要对此服务进行高可用至少需要两个节点。
Rados存储集群
RADOS为一个Ceph名词,通常指ceph存储集群,英文全名Reliable Automatic Distributed Object Store。即可靠的、自动化的、分布式对象存储系统。
Librados介绍
Librados是RADOS存储集群的API,支持常见的编程语言,如:C、C++、Java、Python、Ruby和PHP等。 通常客户端在操作RADOS的时候需要通过与Librados API接口交互,支持下面几种客户端:
- RBD
- CephFS
- RadosGW
RBD:Rados Block Devices此客户端接口基于Librados API开发,通常用于块设备存储,如虚拟机硬盘。支持快照功能。 RadosGW:此客户端接口同样基于Librados API开发,是一个基于HTTP Restful风格的接口。 CephFS:此客户端原生的支持,通常文件系统存储的操作使用CephFS客户端。如:NFS挂载。
管理节点
Ceph常用管理接口通常都是命令行工具,如rados、ceph、rbd等命令,另外Ceph还有可以有一个专用的管理节点,在此节点上面部署专用的管理工具来实现近乎集群的一些管理工作,如集群部署,集群组件管理等。
Pool与PG
Pool是一个存储对象的逻辑分区,它通常规定了数据冗余的类型与副本数,默认为3副本。对于不同类型的存储,需要单独的Pool,如RBD。每个Pool内包含很多个PG。 PG是归置组,英文名为Placement Group,它是一个对象的集合,服务端数据均衡和恢复的最小单位就是PG。
FileStore与BlueStore
FileStore是老版本默认使用的后端存储引擎,如果使用FileStore,建议使用xfs文件系统。 BlueStore是一个新的后端存储引擎,可以直接管理裸硬盘,抛弃了ext4与xfs等本地文件系统。可直接对物理硬盘进行操作,同时效率也高出很多。
Object对象
在Ceph集群中,一条数据、一个配置都为一个对象。这些都是存储在Ceph集群,以对象进行存储。每个对象应包含ID、Binary Data和Metadata。
工作原理
底层存储机制:RADOS把多个节点组织为一个集群,并利用对方的存储空间整合成更大的存储空间,从而提供分布式存储服务。
图
https://www.modb.pro/db/634328 一句话概括:对象映射给PG—-》PG映射给osd,过程由CRUSH算法来完成。
部署Ceph
环境
硬件:
- 服务器:2288H V5
- Cpu:Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz // 90.91.33.57, 90.91.33.58, 90.91.33.60, 90.91.33.62
OS:
- CentOS Linux release 7.6.1810 (Core)
个人环境:
| 主机名 | IP | 网卡模式 | 内存 | 系统盘 | 数据盘 | 备注 |
|---|---|---|---|---|---|---|
| ceph-1(node57) | 90.91.33.57 | cpu | ||||
| ceph-2(node58) | 90.91.33.58 | cpu | ||||
| ceph-3(node60) | 90.91.33.60 | cpu | ||||
| ceph-client(node62) | 90.91.33.62 | cpu |
基础配置
修改主机名称
修改主机名为了方便区分,不改也可以,可以区分开就好。
主机配置为ceph1, ceph2, ceph3; 客户机配置为ceph-client
1 2 3 4 5 6 7 8
[root@localhost ~]# hostnamectl set-hostname ceph-1 [root@ceph-1 ~]# bash [root@localhost ~]# hostnamectl set-hostname ceph-2 [root@ceph-2 ~]# bash [root@localhost ~]# hostnamectl set-hostname ceph-3 [root@ceph-3 ~]# bash [root@localhost ~]# hostnamectl set-hostname ceph-client [root@ceph-clinet ~]# bash
配置hosts文件映射
1
vim /etc/hosts
在各个集群和客户端节点的“/etc/hosts”中添加如下内容:
1 2 3 4
90.91.33.57 node57 90.91.33.58 node58 90.91.33.60 node60 90.91.33.62 node62
关闭防火墙 关闭本节点防火墙,需在所有Ceph节点和Client节点依次执行如下命令。
1 2 3
systemctl stop firewalld systemctl disable firewalld systemctl status firewalld
配置ssh免密登录 使用 ssh-keygen 命令生成公钥、私钥(一直按回车),再使用 ssh-copy-id 命令将公钥copy复制到目标主机,最后使用一个for循环测试是否可免密登录。 在node57(ceph-1)上操作
1 2 3 4 5
ssh-keygen -t rsa ssh-copy-id node57 ssh-copy-id node58 ssh-copy-id node60 ssh-copy-id node62测试是否可免密登录
1
for i in 57 58 60 62; do ssh node$i hostname; done
配置yum源 在所有集群和客户端节点配置epel源。
1
yum install epel-release -y
配置时间同步 Ceph为什么要时间同步?
1
它是一个分布式存储系统,其中的各个节点需要协同工作。如果节点之间的时间不同步,可能会导致数据不一致或者丢失。例如,如果某个节点的时间比其他节点早,它可能会认为某个对象已经被删除,而其他节点还在继续使用该对象。这种不一致性可能会导致数据损坏或丢失。因此,为了保证数据的一致性和可靠性,Ceph要求节点之间的时间同步。
node57节点执行:
1 2 3 4 5
[root@node57 /]# sed -i '3,6s/^/#/g' /etc/chrony.conf [root@node57 /]# sed -i '7s/^/server ceph-1 iburst/g' /etc/chrony.conf [root@node57 /]# echo "allow 90.91.33.0/24" >> /etc/chrony.conf [root@node57 /]# echo "local stratum 10" >> /etc/chrony.conf [root@node57 /]# systemctl restart chronyd && systemctl enable chronyd
node58, node60, node62节点执行:
1 2 3 4
sed -i '3,6s/^/#/g' /etc/chrony.conf sed -i '7s/^/server node57 iburst/g' /etc/chrony.conf systemctl restart chronyd && systemctl enable chronyd chronyc sources
创建ceph集群
安装ceph软件
配置Ceph镜像源
在所有集群和客户端节点建立ceph.repo。
1
vi /etc/yum.repos.d/ceph.repo
加入如下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
[Ceph] name=Ceph packages for $basearch baseurl=http://download.ceph.com/rpm-nautilus/el7/$basearch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc priority=1 [Ceph-noarch] name=Ceph noarch packages baseurl=http://download.ceph.com/rpm-nautilus/el7/noarch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc priority=1 [ceph-source] name=Ceph source packages baseurl=http://download.ceph.com/rpm-nautilus/el7/SRPMS enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc priority=1
更新Yum源
1
yum clean all && yum makecachenode57
1 2
yum install ceph-deploy ceph python-setuptools -y ceph-deploy --version
node58, node60
1
yum install ceph python-setuptools -y
如果安装提示以下错误信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44
Error: Package: 2:ceph-radosgw-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0()(64bit) Error: Package: 2:librbd1-14.2.11-0.el7.x86_64 (ceph) Requires: liblttng-ust.so.0()(64bit) Error: Package: 2:ceph-base-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0()(64bit) Error: Package: 2:librados2-14.2.11-0.el7.x86_64 (ceph) Requires: liblttng-ust.so.0()(64bit) Error: Package: 2:ceph-base-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0(LIBOATH_1.10.0)(64bit) Error: Package: 2:ceph-base-14.2.11-0.el7.x86_64 (ceph) Requires: liblttng-ust.so.0()(64bit) Error: Package: 2:ceph-common-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0(LIBOATH_1.10.0)(64bit) Error: Package: 2:ceph-mon-14.2.11-0.el7.x86_64 (ceph) Requires: libleveldb.so.1()(64bit) Error: Package: 2:ceph-osd-14.2.11-0.el7.x86_64 (ceph) Requires: libleveldb.so.1()(64bit) Error: Package: 2:ceph-base-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0(LIBOATH_1.2.0)(64bit) Error: Package: 2:ceph-common-14.2.11-0.el7.x86_64 (ceph) Requires: libleveldb.so.1()(64bit) Error: Package: 2:ceph-common-14.2.11-0.el7.x86_64 (ceph) Requires: libbabeltrace.so.1()(64bit) Error: Package: 2:ceph-common-14.2.11-0.el7.x86_64 (ceph) Requires: libbabeltrace-ctf.so.1()(64bit) Error: Package: 2:ceph-mgr-14.2.11-0.el7.x86_64 (ceph) Requires: python-bcrypt Error: Package: 2:ceph-common-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0(LIBOATH_1.2.0)(64bit) Error: Package: 2:ceph-base-14.2.11-0.el7.x86_64 (ceph) Requires: libleveldb.so.1()(64bit) Error: Package: 2:librgw2-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0()(64bit) Error: Package: 2:ceph-mgr-14.2.11-0.el7.x86_64 (ceph) Requires: python-pecan Error: Package: 2:ceph-base-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0(LIBOATH_1.12.0)(64bit) Error: Package: 2:librgw2-14.2.11-0.el7.x86_64 (ceph) Requires: liblttng-ust.so.0()(64bit) Error: Package: 2:ceph-common-14.2.11-0.el7.x86_64 (ceph) Requires: liboath.so.0()(64bit) You could try using --skip-broken to work around the problem You could try running: rpm -Va --nofiles --nodigest
这时候需要更新安装一下依赖包 ,就可以完美解决
1
yum install -y yum-utils && yum-config-manager --add-repo https://dl.fedoraproject.org/pub/epel/7/x86_64/ && yum install --nogpgcheck -y epel-release && rpm --import /etc/pki/rpm-gpg/R
部署MON节点
仅需在主节点node57节点上执行。
ceph.conf:ceph配置文件 ceph-deploy-ceph.log:日志文件 ceph.mon.keyring:mon密钥文件(mon之间通信会用到)
创建集群:
1 2
cd /etc/ceph ceph-deploy new node57 node58 node60在“/etc/ceph”目录下自动生成的ceph.conf文件中配置网络mon_host、public network、cluster network
1
vim /etc/ceph/ceph.conf
将ceph.conf中的内容修改为如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
[global] fsid = 8743b02c-4e8c-4650-bdd6-0f9c4f0fd0f7 mon_initial_members = node57, node58, node60 mon_host = 90.91.33.57,90.91.33.58,90.91.33.60 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx public_network = 90.91.33.0/24 cluster_network = 90.91.33.0/24 [mon] mon_allow_pool_delete = true
public_network用于存储节点与计算节点的数据交互,cluster_network用于内部存储集群之间的数据同步(仅在存储节点间使用),目的是将内部集群间的网络与外部访问的网络隔离,通常应该是不同的Ip。
初始化监视器并收集密钥:
1
ceph-deploy mon create-initial
将“ceph.client.admin.keyring”拷贝到各个节点上
1
ceph-deploy --overwrite-conf admin node57 node58 node60 node62
查看是否配置成功
1
ceph -s
部署MGR节点
仅需在主节点node57节点上执行。
1
ceph-deploy mgr create node57 node58 node60
查看MGR是否部署成功
1
ceph -s结果如下所示:
部署OSD节点 “sda”代表系统中的第一个磁盘,而“sdb”、“sdc”则代表系统中的第二个磁盘和第三个磁盘。如果系统中有更多的磁盘,则可以继续使用“sd”命名方式,例如“sdd”、“sde”等等。 在ceph集群中。Administrators、Monitors、Managers和MDSs节点节点对服务器硬盘都没有要求,只要系统能正常运行即可。但OSD节点不一样,通常一个OSD就代表一块物理硬盘,作为分布式存储,OSD越多越好。 划分OSD分区:
查看各服务器磁盘占用情况:
1
lsblk
node57 sdb磁盘空闲,可用用作OSD。
node58 没有空闲磁盘可供OSD使用
node60
sdb磁盘空闲,可用用作OSD。
在node57,node60的sdb上划分10GB的空间作为OSD。
创建分区
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
[root@node57 ceph]# sudo parted /dev/sdb GNU Parted 3.1 Using /dev/sdb Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) mklabel msdos (parted) unit GB (parted) mkpart Partition type? primary/extended? primary File system type? [ext2]? ext4 Start? 0.00GB End? 10.00GB (parted) print Model: HUAWEI HWE52SS36T4M002N (scsi) Disk /dev/sdb: 6401GB Sector size (logical/physical): 512B/4096B Partition Table: msdos Disk Flags: Number Start End Size Type File system Flags 1 0.00GB 10.0GB 10.0GB primary
- sdb下已新增分区sdb1
格式化分区
将/dev/sdb1分区格式化为ext4类型
1
ext4是一种Linux文件系统类型,是ext3文件系统的后继版本。它是Linux内核的一部分,支持更大的文件和分区大小,更快的文件系统检查和更好的性能。它还提供了更好的数据一致性和更高的可靠性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
```bash [root@node57 ceph]# sudo mkfs.ext4 /dev/sdb1 mke2fs 1.42.9 (28-Dec-2013) Discarding device blocks: done Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 610800 inodes, 2441216 blocks 122060 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=2151677952 75 block groups 32768 blocks per group, 32768 fragments per group 8144 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632 Allocating group tables: done Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done ``` ```输入“lsblk -f”并按回车,查看/dev/sdb1是否格式化为ext4类型。 ```
挂载分区(用作OSD的分区会被Ceph独占,不能挂载文件夹,跳过此步)
1 2 3 4 5
创建文件夹`/data`,将分区sdb1挂载在上面。 ```bash [root@node57 ceph]# sudo mkdir /data [root@node57 ceph]# sudo mount /dev/sdb1 /data检查是否成功挂载上新创建的分区。
1 2 3
[root@node57 ceph]# df -h /dev/sdb1 Filesystem Size Used Avail Use% Mounted on /dev/sdb1 9.1G 37M 8.6G 1% /data
部署OSD节点
node57执行
1 2
ceph-deploy osd create node57 --data /dev/sdb1 ceph-deploy osd create node60 --data /dev/sdb1
创建OSD失败,错误信息如下:/dev/sdb1已经挂载,因此不能独占访问。
原因:sdb1已经挂载了文件夹
/data,在独占访问文件系统之前,需要卸载/data。1
sudo umount /dev/sdb1查看osd状态
1
ceph -s2个osd的状态都是up
使用Ceph
Ceph是一个集可靠性、可扩展性、统一性的分布式存储系统,提供对象(Object)、块(Block)及文件系统(File System)三种访问接口,它们都通过底层的 LIBRADOS 库与后端的对象存储单元(Object Storage Device,OSD)交互,实现数据的存储功能。
CephFs文件系统
配置MDS节点 MDS(Metadata Server)即元数据Server主要负责Ceph FS集群中文件和目录的管理。配置MDS节点如下: 创建MDS。在node57节点执行:
1 2
cd /etc/ceph ceph-deploy mds create node57 node58 node60在Ceph各个节点上查看是否成功创建MDS进程。
1
ps -ef | grep ceph-mds | grep -v grep
创建存储池和文件系统
CephFS需要使用两个Pool来分别存储数据和元数据,分别创建fs_data和fs_metadata两个Pool。 Ceph集群中的PG总数:
1
PG总数 = (OSD总数 * 100) / 最大副本数
结果必须舍入到最接近的2的N次方幂的值,本例中取128。 在node57上执行以下命令创建存储池。
1 2
ceph osd pool create fs_data 128 128 ceph osd pool create fa_metadata 64 64
命令中的fs_data是存储池名字,128分别是pg、pgp的数量,fs_metadata同理。
基于上述存储池创建新的文件系统。
1
ceph fs new cephfs fs_metadata fs_data
cephfs为文件系统名称,fs_metadata和fs_data为存储池名称,注意先后顺序。 查看创建的CephFS。
1
ceph fs ls客户机挂载文件系统 在Client节点node62查看客户端访问Ceph集群密钥。
1
cat /etc/ceph/ceph.client.admin.keyring创建文件系统挂载点,在node62执行。
1
mkdir /mnt/cephfs在node62执行。
1
mount -t ceph 90.91.33.57:6789,90.91.33.58:6789,90.91.33.60:6789:/ /mnt/cephfs -o name=admin,secret=AQCgfVRl06p9DhAAvx2FeW++PyH5OXuCURk0wg==,sync
MON默认端口号为6789,-o参数指定集群登录用户名和密钥(secret=步骤1查看到的key)。在node62检查是否挂载成功,文件系统类型是否为ceph。
1
stat -f /mnt/cephfs
块存储
创建存储池,存储池命名为vdbench。
1 2
cd /etc/ceph ceph osd pool create vdbench 8 8
Ceph 14.2.22版本创建存储池后,需指定池类型(CephFS、RBD、RGW)三种,本文以创建块存储为例。
1
ceph osd pool application enable vdbench rbd创建块设备 创建两个块设备image1、image2
1 2
rbd create image1 -s 2048 --pool vdbench --image-format 2 --image-feature layering rbd create image2 -s 2048 --pool vdbench --image-format 2 --image-feature layering
查看image1 检查是否创建成功
1
rbd ls -p vdbench
输出结果中包含image1、image2,说明创建成功。